이번 글에서는 딥러닝 프로젝트 진행 도중에 흔히 직면하는 문제점들과 이를 해결하기 위한 다양한 기법, 그리고 모델 성능을 높이기 위해 시도할 수 있는 여러 방법에 대해 좀 더 자세하게 살펴보자.
1. 오버피팅(Overfitting) & 언더피팅(Underfitting)
딥러닝(혹은 머신러닝) 모델을 학습하다 보면 오버피팅과 언더피팅 문제를 자주 마주하게 된다.
1.1 오버피팅(Overfitting)
오버피팅이란 모델이 학습 데이터에 지나치게 맞춰져서, 정작 새로운 데이터(테스트나 실제 환경의 데이터)에는 일반화가 잘 되지 않는 상태를 말한다.
주요 징후:
- 학습 데이터에 대한 정확도(accuracy)는 매우 높음
- 검증/테스트 데이터에 대한 정확도는 현저히 낮음
- 학습 손실(train loss)은 낮지만 검증 손실(valid loss)은 높아지는 추세
1.2 언더피팅(Underfitting)
언더피팅은 반대로, 모델이 충분한 학습을 하지 못해 학습 데이터조차 제대로 예측하지 못하는 상황을 말한다.
주요 징후:
- 학습 정확도 자체가 낮음
- 학습 손실(train loss)이 높은 상태에서 더 이상 개선되지 않음
1.3 해결책
- 데이터 증강(Data Augmentation)
- 이미지 회전, 뒤집기, 자르기, 색상 변환 등으로 데이터 다양성 확보
- 텍스트 데이터의 경우 Synonym Replacement, Back-translation 등
transform = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), ])
2. **정규화(Regularization) 기법**
- L2 정규화(Weight Decay): 모델 파라미터가 너무 커지지 않도록 제어
- Dropout: 뉴런 일부를 확률적으로 비활성화하여 과적합 방지
- Batch Normalization: 각 배치마다 입력을 정규화해, 학습 안정성 향상
```python
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Linear(784, 128)
self.dropout = nn.Dropout(p=0.3) # 드롭아웃
self.layer2 = nn.Linear(128, 10)
def forward(self, x):
x = self.flatten(x)
x = F.relu(self.layer1(x))
x = self.dropout(x)
return self.layer2(x)
```
3. **조기 종료(Early Stopping)**
- 학습 과정에서 검증 손실(validation loss)이 일정 에폭(epoch) 동안 개선되지 않으면 학습을 미리 중단
- 불필요하게 오랫동안 학습함으로써 발생하는 오버피팅 방지
2. 하이퍼파라미터 튜닝(Hyperparameter Tuning)
하이퍼파라미터는 학습률(learning rate), 배치 크기(batch size), 은닉층의 크기 등 모델 구조나 학습 방식에 영향을 주는 모든 파라미터를 통칭한다. 올바른 하이퍼파라미터 값을 찾는 것은 모델 성능에 지대한 영향을 미친다.
2.1 검색 전략
-
Grid Search
- 미리 정한 후보들의 모든 조합을 시도
- 연산 비용이 매우 큼
- 적은 파라미터 범위에서는 어느 정도 유효
-
Random Search
- 정해진 범위 안에서 무작위로 파라미터를 선택해 실험
- 많은 실험 중 일부가 좋은 파라미터 영역을 커버하기 때문에 의외로 효율적
-
Bayesian Optimization
- Optuna, Hyperopt 등 라이브러리를 사용
- 이전 실험 결과를 토대로 다음 실험에서 시도할 하이퍼파라미터를 탐색
- 비교적 적은 횟수의 실험으로도 최적값에 접근 가능
import optuna
def objective(trial):
lr = trial.suggest_float('lr', 1e-5, 1e-1, log=True)
batch_size = trial.suggest_categorical('batch_size', [16, 32, 64])
# ... 모델 정의 및 학습 로직 ...
# ... 검증(Validation) 점수 계산 ...
return validation_loss
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=30)
print(study.best_params)
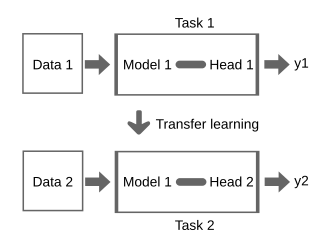
3. 전이 학습(Transfer Learning)
전이 학습은 이미 학습된 모델(예: ImageNet으로 학습된 ResNet, BERT 등)을 활용해, 새로운 작업에 빠르게 적응시키는 기법이다.
- 장점: 데이터가 많지 않아도 높은 성능을 얻을 수 있음
- 대표 예시: ImageNet 사전학습 모델(ResNet, VGG, EfficientNet 등), NLP 분야의 BERT, GPT 등
import torchvision.models as models
# 이미 학습된 ResNet50 불러오기
model = models.resnet50(pretrained=True)
# 마지막 층(fully connected layer)만 교체
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10) # 예: 클래스 10개
전이 학습은 학습 시간을 단축시키고, 성능을 빠르게 끌어올릴 수 있는 좋은 선택지다.
4. 모델 해석(Explainability)과 시각화

복잡한 모델이 예측 결과를 도출하는 과정을 파악하고, 왜 이런 예측이 나왔는지를 설명하는 것은 점점 더 중요해지고 있다.
-
Grad-CAM
- CNN 계열 모델에서 입력 이미지의 어떤 부분이 예측에 중요한 영향을 주었는지 시각화
- 클래스별 활성화 맵을 확인해, 모델이 주로 집중하는 영역을 파악
-
SHAP (SHapley Additive exPlanations)
- 특성(feature)별로 예측에 기여하는 정도를 정량적으로 산출
- 트리 기반 모델, 신경망, 선형 모델 등 다양한 모델에 적용 가능
-
LIME (Local Interpretable Model-Agnostic Explanations)
- 모델 주변의 국소(local) 영역을 단순화된 모델로 근사
- 예측의 원인을 직관적으로 해석할 수 있도록 돕는 기법
마치며
이번 글에서는 오버피팅/언더피팅, 하이퍼파라미터 튜닝, 전이 학습 등 딥러닝 프로젝트의 실질적인 문제 해결과 성능 향상에 관해 보다 구체적으로 다뤄보았다.